[20.12.23]
> SQL 기본 문법, SECTION02 : 데이터의 변경을 위한 SQL문
INSERT : 데이터의 삽입
/* INSERT문의 기본형식 */
INSERT INTO 테이블 이름(col1, col2, ...) VALUES (val1, val2, ...)- 테이블의 속성이름 (column)부분 생략가능. 단, 생략 시 테이블에 정의된 속성의 순서 및 갯수와 입력하는 값(values)이 동일해야 됨
- AUTO INCREMENT : 데이터가 추가될 때 마다 1부터 자동으로 증가하는 int속성, 적용할 속성이 PRIMARY KEY 또는 UNIQUE일 때만 사용가능하다.
*PRIMARY KEY : 기본 키 설정 시
*UNIQUE : 테이블 속성 내에서 유일한 값 설정 시
+ INSERT INTO ... SELECT 쿼리구문을 사용하여 다른테이블의 데이터를 가져와 대량으로 샘플데이터를 생성할 수 있다.
INSERT INTO (col1, col2, ...) SELECT ... FROM ... WHERE ...;
UPDATE : 데이터의 수정, 기존에 입력되어 있던 값을 변경하는 쿼리
UPDATE 테이블 이름
SET col1 = val1, col2 = val2 ...
WHERE condition;- WHERE 절 생략시 전체 행의 내용이 변경될 수 있음. 원상복구가 어렵거나 되돌릴 수 없는 경우가 있으니 주의가 필요하다.
DELETE : 행 단위로 데이터를 삭제하는 쿼리구문
DELETE FROM 테이블 이름 WHERE condition;- WHERE 절 생략시 전체 테이블 삭제됨
> SQL 고급 문법, SECTION01 : MySQL의 데이터 형식
숫자데이터 형식

문자 데이터 형식
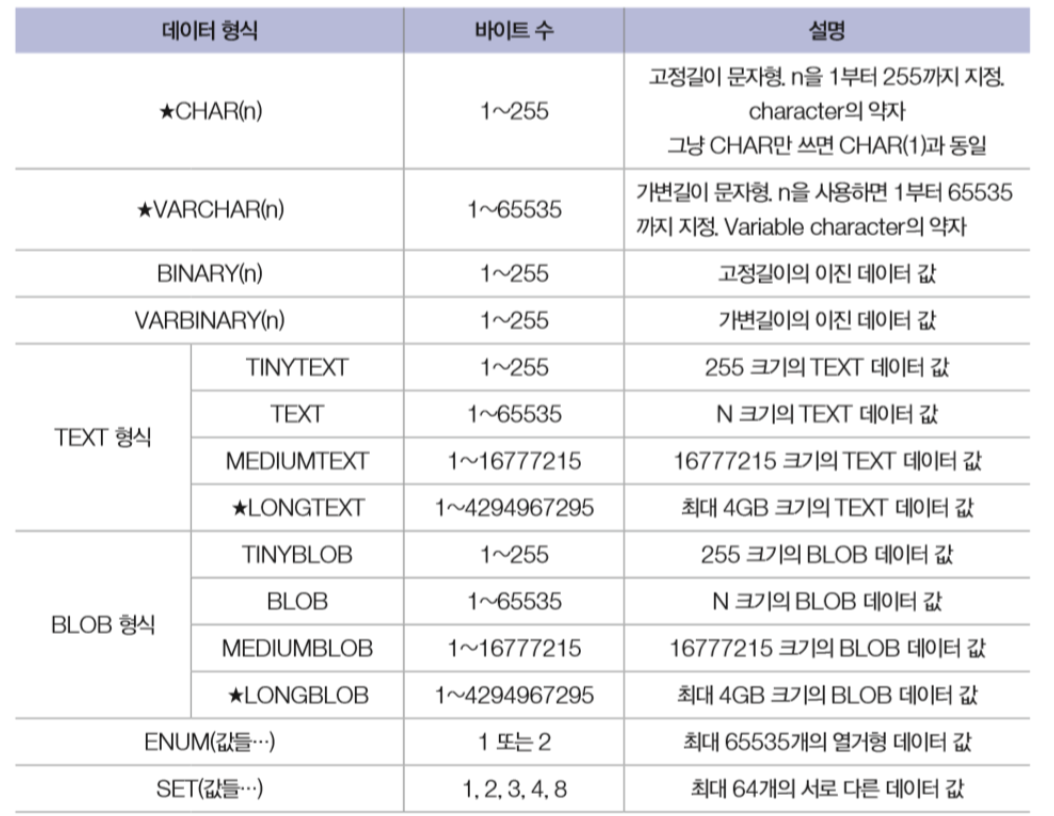
MySQL 내장함수(일부)
- LOWER(), UPPER() : 문자열 함수, 대소문자 전환
- CURDATE(), CURTIME() : 현재 연- 월- 일 / 현재 시: 분 : 초 출력
- NOW(), SYSDATE() : 현재 연- 월- 일 시: 분 : 초 출력
- DATEDIFF(a, b) : 두 날짜간 차이 구하는 함수
> SQL 고급 문법, SECTION02 : 조인(JOIN)
* 데이터베이스의 테이블은 중복과 공간낭비를 피하고 데이터의 무결성을 보장하기 위해서 여러개의 테이블로 분리해서 저장한다. 이러한 분리된 테이블들은 서로 관계(Relation)을 가지며 1:N(일대다) 관계가 보편적이다.
조인(JOIN) 이란?
- 두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 기능을 제공하는 쿼리구문이다.
- 종류 : INNER JOIN, OUTER JOIN, CROSS JOIN, SELF JOIN
*조인(JOIN)구문을 설명하기 전에 아래 그림을 통해 대략적인 이해를 하고자 한다.*

INNER JOIN : 가장 일반적으로 사용되는 JOIN, 양 쪽 테이블 모두에서 일치하는 행을 결합시키는 쿼리구문
(LEFT/RIGHT) OUTER JOIN : JOIN의 조건에 만족되지 않는 행 까지도 포함 시키는 쿼리구문, 왼쪽 혹은 오른쪽 테이블의 것은 모두 출력 되어야 한다라고 이해
CROSS JOIN :한 쪽 테이블의 모든 향과 다른 쪽 테이블의 모든 행을 조인시키는 쿼리구문, 테스트로 사용할 많은 용량의 데이터를 생성할 때 사용함으로 일반적인 용도로 사용 할 일은 없다. 대량의 데이터가 생성될 때 시스템이 다운되거나 디스크의 용량이 모두 찰 수 있다.
SELF JOIN :자기 자신의 테이블과 조인한다는 의미 >> 조직도와 관련된 테이블 구성할 시 사용
*실습문제*

USE employees;
-- 1)
SELECT dept_name, first_name, last_name
FROM employees
JOIN dept_emp
ON employees.emp_no = dept_emp.emp_no
JOIN departments
ON departments.dept_no = dept_emp.dept_no;
-- 2)
SELECT dept_name, first_name, last_name
FROM employees
JOIN dept_emp
ON employees.emp_no = dept_emp.emp_no
JOIN departments
ON departments.dept_no = dept_emp.dept_no
WHERE dept_emp.dept_no = 'd007';
-- 3)
SELECT dept_name, first_name, last_name
FROM employees
JOIN dept_emp
ON employees.emp_no = dept_emp.emp_no
JOIN departments
ON departments.dept_no = dept_emp.dept_no
WHERE dept_emp.dept_no = 'd007'
AND employees.gender = 'M';
-- 4)
SELECT dept_name, first_name, last_name
FROM employees
JOIN dept_emp
ON employees.emp_no = dept_emp.emp_no
JOIN departments
ON departments.dept_no = dept_emp.dept_no
WHERE dept_emp.dept_no = 'd007'
AND employees.gender = 'M'
AND (employees.hire_date BETWEEN '2000-01-01' AND '2001-01-01');
-- 5)
SELECT dept_name, first_name, last_name
FROM employees
JOIN dept_emp
ON employees.emp_no = dept_emp.emp_no
JOIN departments
ON departments.dept_no = dept_emp.dept_no
WHERE dept_emp.dept_no = 'd007'
AND employees.gender = 'M'
AND (employees.hire_date BETWEEN '2000-01-01' AND '2001-01-01');
ORDER BY employees.first_name ASC;
-- 6)
SELECT first_name, last_name
FROM employees
JOIN titles
ON employees.emp_no = titles.emp_no
WHERE titles.title = 'Staff';
-- 7)
SELECT AVG(salary)
FROM salaries
JOIN titles
ON salaries.emp_no = titles.emp_no
WHERE titles.title = 'Staff';
-- 8)
SELECT title, AVG(salary)
FROM salaries
JOIN titles
ON salaries.emp_no = titles.emp_no
GROUP BY titles.title;> 테이블과 뷰
지금까지는 예제 데이터베이스를 가져와서 테이블 조회 및 데이터 삽입,삭제 등의 작업을 수행하였다. 지금부터는 테이블을 생성 및 관리하는 법과 기존테이블로 부터 가상테이블을 유도하는 뷰(VIEW)에 대해서 알아보자.
테이블 생성 및 관리:
- 테이블 생성 : CREATE TABLE 테이블이름( 테이블 속성 콤마(,)로 구분 );
CREATE TABLE buyertbl(
);
- 제약조건 : 데이터의 무결성을 지키기 위한 조건을 제한하는 것, 특정 데이터를 입력 시 어떠한 조건을 만족했을 때에 입력되도록 제약
- 데이터 무결성을 위한 제약조건 :
• PRIMARY KEY 제약 조건 : 수 많은 데이터 중에서 특정 행을 구분할 수 있는 식별자, NULL, 중복을 허용하지 않는다
• FOREIGN KEY 제약 조건 : 테이블 간의 관계를 선언하며 하나의 테이블이 다른 테이블에 의존하게 된다. 이 때 참조되는 테이블의 열은
반드시 PRIMARY KEY이거나 UNIQUE제약조건이 설정되어 있어야 한다
• UNIQUE 제약 조건 : 중복되지 않는 유일한 값을 입력해야하는 조건, NULL을 허용하는 점에서 PRIMARY KEY와 구분된다.
• CHECK 제약 조건 : 입력되는 값을 점검하는 기능, 특정 조건을 충족하지 않으면 값이 입력되지 않는다.
• DEFAULT 정의 : 값을 입력하지 않았을 때 자동으로 입력되는 기본 값을 정의하는 기눙
• NULL 값 허용 : 값을 입력하지 않아도 되는 속성, NULL 값을 허용하려면 NULL을, 허용하지 않으려면 NOT NULL을 사용
CREATE TABLE usertbl(
prod_id VARCHAR(20) PRIMARY KEY #기본 키
,email VARCHAR(30) UNIQUE #UNIQUE 제약조건
,BirthYear INT CHECK(BirthYear < 2003) #CHECK 제약조건
,addr VARCHAR(20) DEFAULT 'Seoul' #DEFAULT 제약조건
,mobile VARCHAR(20) NULL #NULL 허용
);
CREATE TABLE buytbl(
prod_id VARCHAR(20) INT AUTO_INCREMENT PRIMARY KEY #AUTO_INREMENT : 자동으로 증가하는 수
,user_id VARCHAR(20) #------------------
,FOREIGN KEY (user_id) #FOREIGN KEY 제약조건
REFERENCES usertbl(user_id) #------------------
);- 테이블 삭제 : 외래 키 제약 조건의 기준 테이블은 삭제할 수가 없다
DROP TABLE buytbl;- 테이블 변경 : 테이블에 무엇인가 추가/변경/수정/삭제 모두 ALTER TABLE문 사용한다.
ALTER TABLE usertbl ADD homepage VARCHAR(50); #열 추가
ALTER TABLE usertbl CHANGE COLUMN user_id userid CHAR(30); #열 이름 및 형식 변경
ALTER TABLE usertbl DROP email; #열 삭제
뷰(VIEW)
뷰는 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블이다. 저장장치 내에 물리적으로 존재하지 않지만 사용자에게 있는 것처럼 간주된다. 뷰는 데이터 보정작업, 처리과정 시험 등 임시적인 작업을 위한 용도로 활용되며 조인문의 사용 최소화로 사용상의 편의성을 최대화 한다.
- 데이터의 논리적 독립성을 제공
- 필요한 데이터만 뷰로 정의해서 처리할 수 있기 때문에 명령문이 간단해진다.
- 뷰를 통해서만 데이터에 접근하게 하면 뷰에 나타나지 않는 데이터를 안전하게 보호할 수 있다(보안성)
CREATE VIEW v_usertbl
AS
SELECT user_id, user_name, addr FROM usertbl;
CREATE VIEW v_userbuytbl
AS
SELECT U.name, B.prodName
FROM usertbl u JOIN buytbl b
ON u.userid = b.userid;
SELECT * FROM ( v_userbuytbl ) ;
'클라우드 아키텍트 양성과정' 카테고리의 다른 글
| [TIL.20.12.22~28] 관계형 데이터 베이스 설계 (0) | 2021.01.28 |
|---|---|
| [TIL.20.12.22~28] Python과 MySQL (0) | 2021.01.27 |
| [TIL.20.12.22~28]데이터베이스 와 MySQL -1 (0) | 2021.01.26 |
| [TIL.20.12.14] Cloud Computing 그리고 AWS (0) | 2021.01.25 |
| 멀티클라우드 아키텍트 양성과정(20.12.14 - )... 한 발 혹은 두 발 늦은 시작 (0) | 2021.01.25 |




댓글